- Published on
Decoding AI Jargon: A Guide to Understanding the Components of Generative AI
- Authors

- Name
- Dan Orlando
- @danorlando1
Navigating the evolving world of artificial intelligence can often feel like wading through a sea of endless jargon and complex concepts. With terms like 'Large Language Models' and 'Model Weights' becoming commonplace in tech conversations and business meetings, it's crucial to cut through the noise and get a clear understanding of what these terms actually mean and how they impact the digital landscape. In this article, we'll demystify the technical lingo that surrounds large language models and explore their revolutionary implications for businesses and beyond. From the intricacies of neural networks to the practical applications of vector databases, we'll dive in to uncover the components of Generative AI systems. By the end, you'll have a foundational understanding of key concepts in the field of Generative AI, empowering you to navigate this transformative technology with confidence.
The aim for this article is to provide non-technical readers and business leaders with a foundational understanding of key concepts in the field of Generative AI.
Large Language Models
Large language models are trained on extensive corpora of data using deep learning techniques. They use neural networks with billions of parameters, called Model Weights, to capture the nuances of language, from syntax to semantics. Once trained, they can perform a wide array of language tasks, such as translation, summarization, question answering, and content generation, often with little to no task-specific data.
The sudden advancement and surge in popularity of language models is due to several factors, including:
- Advances in Hardware: The development of more powerful GPUs and TPUs has made it feasible to train much larger models than before.
- Better Algorithms: Improvements in neural network architectures, like the Transformer, have led to more efficient and effective training methods.
- Availability of Data: The explosion of digital text data has provided the necessary fuel to train these models on diverse language examples.
- Versatility: These models can be fine-tuned for a wide range of tasks, from writing assistance to programming, making them very versatile tools.
- Business Applications: There is a high commercial interest as these models can automate and improve many tasks that involve natural language, such as customer service, content creation, and data analysis.
- Publicity and Accessibility: The release of models by OpenAI, Anthropic, Google, Meta, and others to the public, along with interfaces that make it easy to interact with these models has led to widespread experimentation and adoption.
Model Weights
Model weights in the context of large language models like Generative Pretrained Transformers (GPT), are the internal parameters that the model adjusts through training to accurately predict or generate text.
These weights are numerical coefficients that the language model uses to process and generate language. During training, the model adjusts these weights to minimize the difference between its predictions and the actual outcomes. This process involves large datasets and complex algorithms that iteratively update the weights to capture the patterns and structures inherent in human language. The final set of weights allows the model to perform tasks such as translation, question answering, and text generation by understanding the context and nuances of language input .
Imagine teaching a child to play a guessing game where they must figure out a word that you're thinking of by asking yes-or-no questions. At first, the child might guess randomly, but over time they remember which questions lead to the right answer. In this analogy, the model weights are like the child's memory of which questions are most helpful. The more they play (or train), the better their guesses become.
Embeddings
Embeddings are a method of converting items like words, sentences, or other types of data into a series of numbers (a vector) in a way that captures their meaning, relationships, or patterns. This allows a computer to process and understand the data more effectively to carry out tasks like similarity search.
More specifically, embeddings are a representation of data in a high-dimensional space, where each dimension corresponds to a latent feature that may capture some semantic or syntactic property of the input data. In natural language processing, for instance, word embeddings are used to translate text into a numerical form that machine learning models can understand, preserving the context and meaning of words such that words with similar meaning have similar vector representations .
Imagine you have a collection of fruits, and you want to organize them based on their characteristics, like sweetness, color, and size. Instead of writing a description for each fruit, you rate these characteristics on a scale, say from 1 to 10. Now, every fruit is represented by a list of numbers, with each number showing how strong a particular characteristic is. This list is like a "fingerprint" for each fruit that you can use to compare them, find out which ones are similar, or group them into categories.
Below: Visualizing the "embeddings" of fruit in a 3-dimensional space defined by their characteristics, which can be extended to more dimensions in real-world applications.
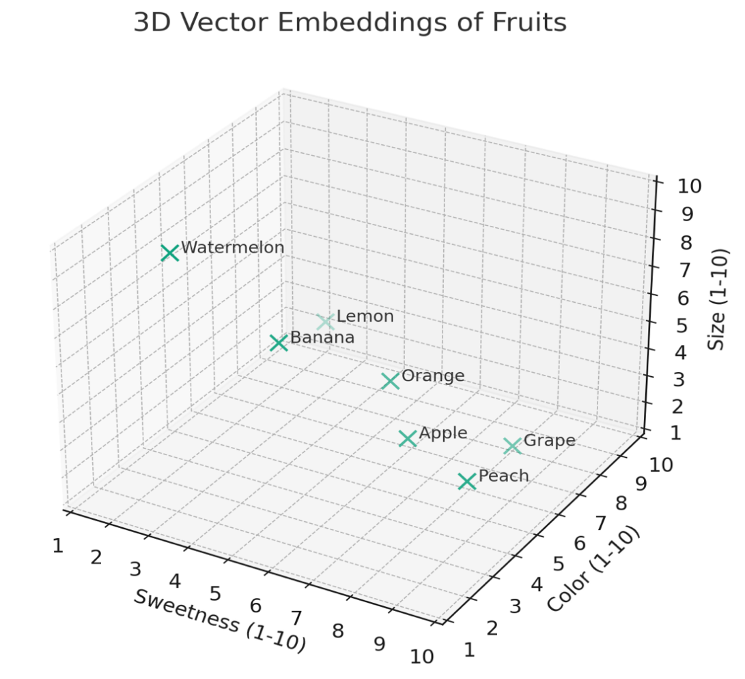
Fun fact: This diagram was generated by inserting the previous paragraph into an LLM chat prompt and asking for an illustration. This demonstrates the model's ability to generate charts and graphs for something like a custom reporting agent, for example.
Vector Database
A vector database is a specialized database designed to efficiently store and manipulate vectors. Vectors are essentially lists of numbers that represent various features or attributes, and in the case of LLMs, they are used to represent linguistic features extracted from text.
In natural language processing (NLP), LLMs like GPT-3 or GPT-4 convert words, phrases, or entire documents into high-dimensional vector representations, often known as embeddings. These embeddings capture the semantic and contextual nuances of the language. A vector database enables the storage of these embeddings in a structured format, allowing for rapid retrieval, comparison, and analysis.
The strength of a vector database lies in its ability to perform operations like nearest neighbor searches. This means it can quickly find vectors that are 'close' to a given query vector in terms of their semantic meaning, which is crucial for applications like semantic search, recommendation systems, or even clustering of similar texts. Think of a vector database as a highly organized library for a specific type of book, where each book represents different things using a unique code made up of numbers. In the world of AI and Large Language Models (like GPT-3 or GPT-4), when these models read and try to understand text, they convert the text into a series of numbers. Each series, or 'vector', represents the meaning and context of the words in a way that the computer can understand.
Now, imagine you want to find books in this library that are similar in topic or style. A vector database helps you quickly find these books by looking at their numerical codes and seeing which ones are most alike. It's like having a super-efficient librarian who can instantly recommend books that match what you're looking for, based on how similar their codes are to the one you give them.
So, in simple terms, a vector database in the context of AI and language models is a sophisticated system for storing and finding these number series (vectors) in an efficient way, helping the AI to quickly and accurately understand, categorize, or retrieve information based on language data.
Fine-tuning
In the context of large language models, Fine-tuning is the process of taking a pre-trained model and adjusting it further with additional training to specialize in a particular task or to better understand a specific type of language.
Fine-tuning is a stage in the model training process where a pre-trained model, which has already learned general language patterns from a large dataset, is further trained on a smaller, domain-specific dataset. This additional training allows the model to adjust its weights to better capture the peculiarities and nuances of the specific language use-case it will be deployed in. For example, a model fine-tuned on medical journals would become more adept at medical terminology and reasoning. Fine-tuning can be done on various scales, from adjusting a few top layers to retraining the entire model, depending on the task complexity and the specificity of the language involved .
Imagine you have a general practitioner doctor who is trained to handle all sorts of medical issues. If this doctor decides to become a specialist, like a cardiologist, they will go back to school to learn more about the heart. Fine-tuning a language model is similar; you take a model that knows a lot about general language and "teach" it more about a specific topic or style of communication, like legal documents or casual conversation, so it can perform better in those areas.
Inference
In the context of Large Language Models (LLMs) like GPT-3 or GPT-4, inference refers to the process of generating responses or predictions based on the input provided to the model. When a user inputs a query or a prompt into an LLM, the model performs inference by processing this input through its neural network layers to generate an output that is contextually and semantically aligned with the given input.
Inference in LLMs is a computationally intensive task, as it involves real-time processing of input data through a complex network of millions or billions of parameters. The model, during inference, accesses its pre-trained knowledge (acquired during the training phase on a large corpus of text) and applies it to the specific input to generate relevant, coherent, and contextually appropriate output. This output can range from a continuation of a text, answering questions, generating creative content, or even translating languages.
In simpler terms, when you interact with an AI model like GPT-3 or GPT-4 by typing in a question or a prompt, the AI is doing what we call 'inference'. It's taking your words, thinking about them (using the knowledge it gained during its training on a vast amount of text), and then crafting a reply that makes sense based on what it knows. This process is like the AI figuring out the best possible response to your input, like how a person would think and respond in a conversation.
Tokens
A 'token' represents a basic unit of processing. These models interpret and generate text based on tokens, which can be thought of as pieces of the text. Unlike traditional text processing that might consider 'words' as the basic unit, tokens in LLMs often represent sub-parts of words or multiple words, depending on the model's tokenization algorithm.
Tokenization is the process of converting text into tokens. This involves breaking down complex text into smaller, more manageable parts. Each token could represent a whole word, a part of a word (like a syllable or a base word with affixes), or even punctuation marks and spaces. For instance, the word "unbelievable" might be broken down into smaller tokens like "un", "believ", and "able".
In LLMs, each token is then converted into a numerical representation, allowing the model to process and understand the text. The model's neural network uses these numerical representations to perform tasks like text generation, translation, or answering questions. The number of tokens a model can consider at one time (its 'context window') is crucial as it determines how much of a text the model can understand and respond to in a single instance.
Each token can be a whole word, a part of a word, or even just a punctuation mark. For example, the sentence "I'm happy!" might be broken down into tokens like "I", "'m", "happy", and "!". This breaking down helps the AI to not only read and understand the text but also to respond to it in a meaningful way.
So, when we talk about 'tokens' in LLMs, we're referring to the small chunks of text that these models use to make sense of the language they read and generate. It's like taking a sentence, cutting it into smaller pieces, and then using those pieces to understand the whole picture.
Prompts and Prompt Engineering
Prompting refers to the practice of providing an LLM with an initial piece of text (the prompt) that sets the stage for the model's response. There are usually several layers to a prompt in a business application, which include:
- A system prompt of complex instructions provided by the developer through Prompt Engineering which are invisible to the user.
- Additional context provided by an external data source in the case of Retrieval Augmented Generation.
- The chat history is specific to that conversation.
- The original raw query or a rephrased version of the query that is generated by a separate LLM call.
Prompt engineering exploits the pre-trained knowledge of the LLM to perform specific tasks without further training. It requires an understanding of how the model interprets text, which can involve complex strategies like example-driven prompts (few-shot or zero-shot learning), chaining of tasks within prompts, or manipulating the style and tone of the output. Effective prompt engineering can significantly boost an LLM's performance on a given task, sometimes approaching, or even exceeding the performance of fine-tuned models.
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) is a fancy term that describes a method in natural language processing where a generative model is combined with a retrieval system to enhance the generation of text. Specifically, the system retrieves relevant information from a large data set or corpus and then uses this context to inform the generative model, such as a Transformer-based neural network, to produce more accurate, relevant, and informative responses. This technique allows the model to pull in external knowledge that it was not necessarily trained on, thus augmenting its capabilities, and enabling it to answer questions and generate content that is beyond its initial training data.
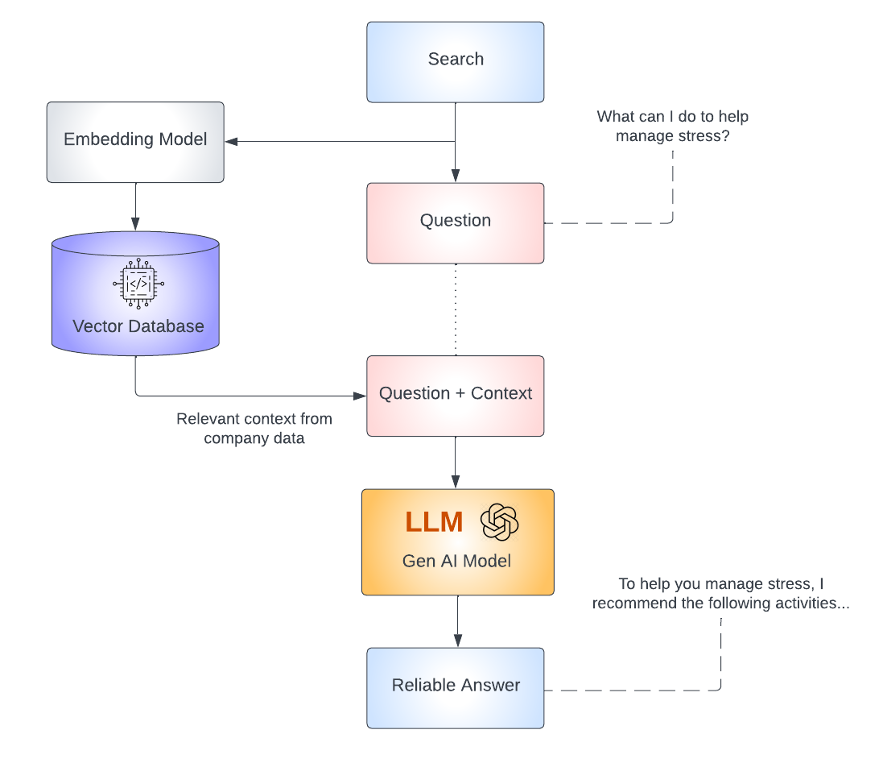
Chains
A Chain in the context of generative AI applications is a sequence of language model operations and external tools or databases linked together to accomplish complex tasks that a single model or tool could not achieve alone. This concept is part of the LangChain framework, which is designed to enhance the capabilities of language models.
In the LangChain framework, "chains" are essentially workflows that can include various components such as:
- Retrieval: Fetching relevant information from external databases or the internet.
- Transformation: Processing the retrieved data to make it usable for the language model.
- Generation: Using a language model to generate text based on the processed data.
- Action: Taking actions based on the generated text, which could include interacting with APIs, databases, or other systems.
The idea is to create a "chain" of actions where the output of one step serves as the input for the next, allowing for more sophisticated interactions and the ability to perform tasks that require external knowledge or capabilities not contained within the model itself. This approach aims to combine the strengths of language models with other tools to create more powerful and versatile AI systems.
Agents
An Agent is a higher-level abstraction within the LangChain framework that encompasses chains and other components (called Tools) to create autonomous entities capable of completing tasks. An agent in the context of LangChain is essentially a program that uses language models as a core part of its operation, but it also integrates other tools and systems to perform actions, such as making calls to external APIs, to provide information that a language model alone could not.
Agents are designed to be:
- Goal-oriented: They have specific tasks or objectives they are trying to achieve.
- Interactive: They can interact with humans or other systems to receive instructions, provide updates, or ask for clarifications.
- Adaptive: They can learn from interactions and improve over time, tailoring their responses and actions to better achieve their goals.
In the LangChain framework, agents can use various chains to handle different aspects of a task. For instance, an agent might have a chain for information retrieval, another for data processing, one for decision-making, and yet another for executing actions. The agent coordinates these chains to complete complex tasks.
The primary difference between Chains and Agents is that a Chain is a predefined flow of actions that will occur every time it is called, whereas an Agent has a certain level of autonomy, where the model is used to break a problem down step-by-step and determine the sequence of actions that should take place to achieve the result before carrying out those actions.
The concept of LangChain agents is about creating systems that can leverage the power of language models while also interacting with and utilizing other systems and data sources, making them more autonomous and effective at carrying out a wide range of tasks.
Conclusion
Mastery of Generative AI and Large Language Models has emerged as a key differentiator in the business arena. This article has endeavored to illuminate the path through the sophisticated terrain of AI language processing, offering business leaders a clear view of the potential that these technologies hold. We've ventured through the complex terminology, uncovered the mechanics of LLMs, and revealed the strategic applications that can propel businesses forward.
In closing, it's clear that the intelligent application of LLMs can be a game-changer in any business context. By integrating these advanced tools, leaders can enhance decision-making, automate nuanced tasks, and unlock new creative avenues. It is our hope that with this foundational understanding, you feel equipped to consider, evaluate, and perhaps even initiate the integration of Generative AI into your business strategies. In doing so, you may not only transform your operations but also contribute to the evolving language of AI, shaping a future where technology and human ingenuity converge to create unprecedented value.